
Introduction to Embeddings in Machine Learning

Have you ever wondered how AI systems like chatbots, virtual assistants, and language translators can understand and process human language so effectively? Driving many of the latest advancements in AI and natural language processing1 is a powerful concept called embeddings. This revolutionary approach has gained momentum over the past decade as machine learning technologies have continued to evolve.
What are Embeddings?
Embeddings are mathematical representations of words, phrases, or even entire documents, that capture their meaning and relationships in the form of a dense vector. you could also read more about vectors in later part of the article.
Unlike traditional methods that treat words as separate units, embeddings group words with similar meanings together in a multi-dimensional space. This allows AI systems to grasp the nuances and relationships between words, much like how humans understand language. For example, in the embedding space, words like "king" and "queen" would be clustered together, while "apple" would be farther away, reflecting their different meanings and contexts.
By representing language in this way, AI models can perform complex calculations and operations to comprehend the intended meaning behind words, phrases, and even entire texts. This enables more accurate and natural language processing, leading to better performance in tasks like language translation, sentiment analysis, and content recommendation.
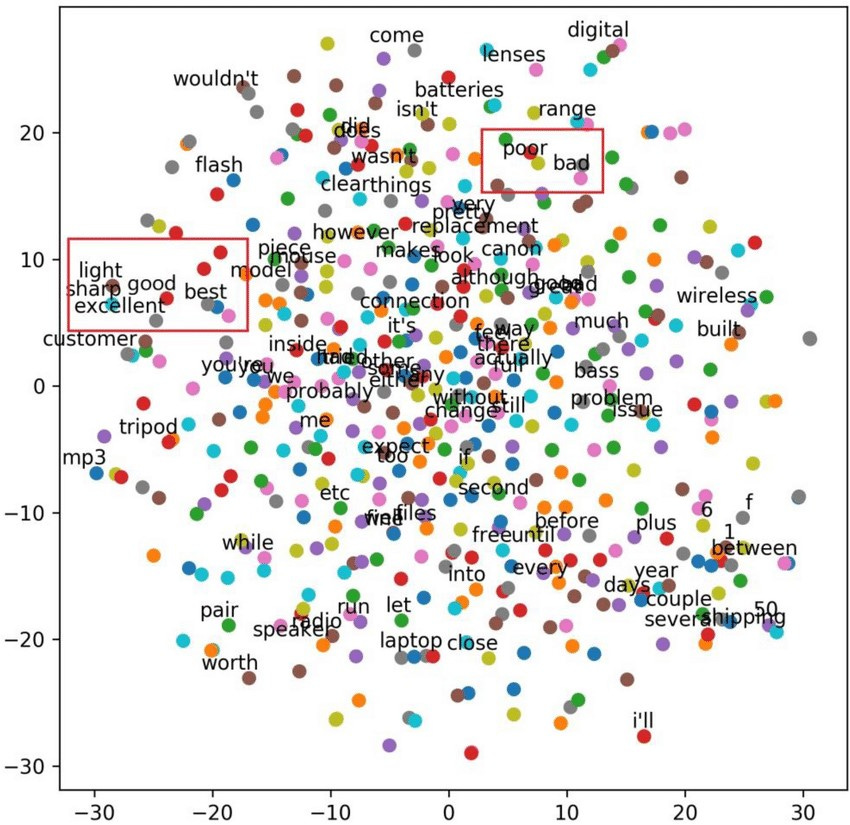
Image2 from the research paper "Learning Deep Representations of Fine-grained Visual Descriptions" (Reed et al., 2016)
Why do Embeddings Exist?
Embeddings offer a compact, simplified way of representing words or documents that captures their meaning and context. This makes it easier for AI models to understand and process language effectively, overcoming the limitations of traditional methods that treat words as isolated units.
Embeddings exist to bridge the gap between human language and machine understanding. They provide a way to represent language in a form that is more easily interpretable by AI systems, enabling them to grasp the nuances, relationships, and contextual information that are inherent in human communication.
How are Embeddings Relevant?
Embeddings have become increasingly relevant in various fields, including natural language processing, computer vision, and recommendation systems, due to their ability to capture complex relationships and patterns in data. They have enabled significant advancements in tasks such as machine translation, sentiment analysis3, text summarization, image recognition, and personalized recommendations.
Vectors vs. Embeddings
Vectors and embeddings are both ways of representing data, but they serve different purposes and are created differently.
Vectors are like simple lists or arrays of numbers. They can represent things like quantities, directions, or positions in space. For example, you could use a vector to represent the coordinates of a location on a map, with each number in the vector representing the latitude, longitude, and altitude.
Embeddings, on the other hand, are more complex representations that are designed to capture the relationships and context between different pieces of data. They are created by machine learning models that analyze large amounts of data and learn to represent that data in a way that preserves its important features and connections.
Think of embeddings like a kind of code or language that the machine learning model creates to represent the data in a way that makes sense to it. For example, if you're working with text data, an embedding might represent each word as a vector of numbers, but those numbers are carefully chosen by the machine learning model to capture the meaning and context of the word, as well as its relationships to other words.
Embeddings are particularly useful for tasks that require understanding and reasoning about complex data, such as natural language processing, image recognition, or recommendation systems. They allow the machine learning model to work with the data in a more meaningful and nuanced way, rather than just treating it as a simple list of numbers or symbols.
While vectors are like simple lists or coordinates, embeddings are like a rich, contextual language that machines can use to better understand and work with complex data.
Analogy - Imagine you have a big box of toys, and each toy represents a different word or object. Vectors are like the toys themselves. Each toy is a vector, and it has a shape and color, but it doesn't really tell you much about what the toy is supposed to be or how it's related to other toys.
Embeddings are like little tags or labels that you can attach to each toy.
These tags have pictures or symbols that give you more information about what the toy represents and how it's related to other toys. For example, if you have a toy dog, the tag on that toy might have a picture of a dog, or it might have symbols that tell you that the word "dog" is related to other words like "pet," "bark," and "furry."
The special thing about embeddings is that they're created by a machine learning model that has learned from a lot of data. This model has figured out which words or objects are related to each other, and it has put the right tags on each toy to show those relationships.
So, when you play with the toys that have embeddings, you can make sure that the toys you're playing with are related to each other in the right way. For example, if you're playing with the toy dog, you can use the toys with the "pet," "bark," and "furry" tags to create a scene that makes sense for a dog.
Vectors are just the toys themselves, but embeddings are like special tags or labels that give you more information about what each toy represents and how it's related to other toys.
Designing Intelligent Products and Delightful Experiences
Embeddings are revolutionizing the way we develop data-driven products and services, enabling us to unlock new possibilities and deliver exceptional user experiences. By representing complex data structures in dense vector spaces, embeddings open up a world of opportunities across various industries. Let's explore some compelling use cases that can be tackled with embedding technology:
Personalized Healthcare Solutions: Embeddings have the potential to transform the healthcare industry by enabling virtual assistants to interpret medical data, patient histories, and conditions. These intelligent systems can then provide personalized recommendations for over-the-counter and prescription medications, empowering patients to make informed decisions and improving overall care.
Enhanced Customer Experiences: In the realm of customer service, embeddings can boost user experiences through accurate language understanding, improved search capabilities, and natural interactions. Multilingual chatbots and virtual assistants can leverage embeddings to communicate seamlessly in users' native languages, delivering personalized experiences that delight customers and foster brand loyalty.
Unlocking Scientific Discoveries: Embeddings can represent complex data structures, such as knowledge graphs or biological sequences, enabling more effective data analysis and insights in domains like scientific research, finance, and healthcare. By uncovering hidden patterns and relationships, embeddings can accelerate scientific discoveries and drive innovation.
Intelligent Content Recommendation Systems:
Embeddings can power intelligent content recommendation systems that understand user preferences, interests, and behaviors. By representing content and user profiles as dense vectors, these systems can provide highly relevant and personalized recommendations, enhancing user engagement and satisfaction across various platforms, from e-commerce to streaming services.
Overall -Embeddings are a powerful concept in machine learning that enable more effective representation and understanding of complex data structures. They are used in a wide range of applications, from language understanding and translation to recommendation systems and computer vision.
Thank you for reading through the article. If you learned something new today, I'd love to hear your thoughts in the comments!
Sources:
https://learn.microsoft.com/en-us/semantic-kernel/memories/embeddings